|
Christopher AmatoAssociate ProfessorKhoury College of Computer Sciences Northeastern University camato at ccs dot neu dot edu
Home | Publications | Research | Robot videos | Talks | Teaching | Group | Contact |
Research: This page hasn't been updated in a few years, so also check out the robot videos and our group web page (the Lab for Learning and Planning in Robotics). |
Optimal coordination of
decentralized agents
My research has made several contributions to Dec-POMDP solutions, including:
|
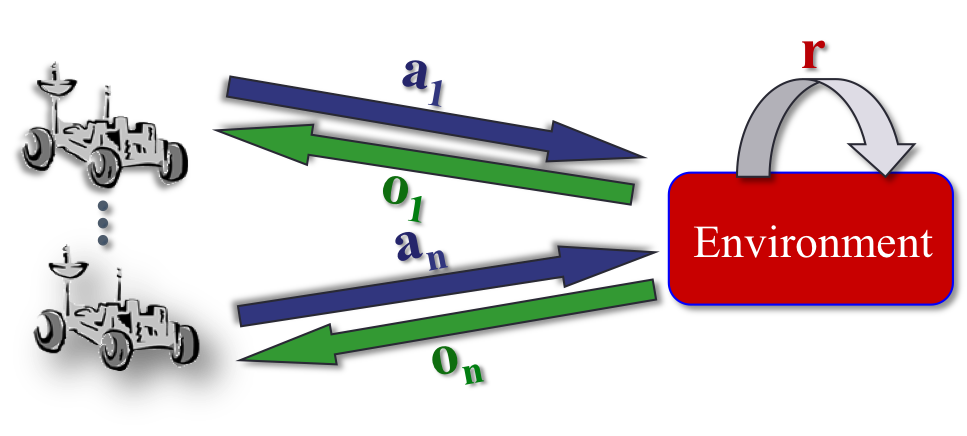
Coordination in multi-robot
systems
A large focus of my current work has been on coordination for teams of robots when there is sensor uncertainty and limited communication. Previous research has addressed parts of the problem or specific instances, but our approaches are the first general and scalable methods that consider uncertainty in the outcomes, sensors and communication. My research has made several contributions to multi-robot coordination, including:
|

Learning to coordinate through
data and interaction
It is time-consuming for humans to generate models and they will often be incorrect or incomplete. This is especially true in multiagent systems where agents often require a model not only for the system, but also for the other agents. As a result, agents must be able to learn these models or learn a solution without using a model. My work has developed scalable methods for learning in different settings:
|

Optimizing agent performance
with limited resources
When only a single agent is present or centralization is possible, POMDPs are a natural model for sequential decision-making with action and sensor uncertainty. In both POMDPs and Dec-POMDPs, solutions can become large and complicated, but searching through and representing these solutions can be computationally intractable. My research has developed fixed-memory approaches that can often provide scalable, high quality solutions:
|

Improving scalability in
algorithms for uncertain decentralized systems
Although finding optimal solutions for Dec-POMDPs can be difficult, we can often find high quality approximate solutions and some problems permit more scalability due to their structure. My research has developed: |

Balancing time and accuracy in
video surveillance
With the profusion of video data, automated surveillance and intrusion detection is becoming closer to reality. In order to provide a timely response while limiting false alarms, an intrusion detection system must balance resources (e.g., time) and accuracy. We showed how such a system can be modeled with a partially observable Markov decision process (POMDP), representing possible computer vision filters and their costs in a way that is similar to human vision systems [IAAI 12]. |

Machine learning for video
games
Video games provide a rich testbed for artificial intelligence methods. In particular, creating automated opponents that perform well in strategy games is a difficult task. For instance, human players rapidly discover and exploit the weaknesses of hard coded strategies. To build better strategies, we developed a reinforcement learning approach for learning a policy that switches between high-level strategies [AAMAS 10]. |