Goal: extract all unigrams from elastic search and dump them into local files.
Step 0: first look on dataset.
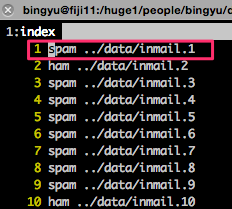
Dataset: spam trec 07, which is a email messages dataset. Total number of email messages = 75,419.
There are two parts for this dataset:
1) file_name: ./full/index, for example the first email, which is a spam, and the original email message is stored in ./data/inmail.1 file.
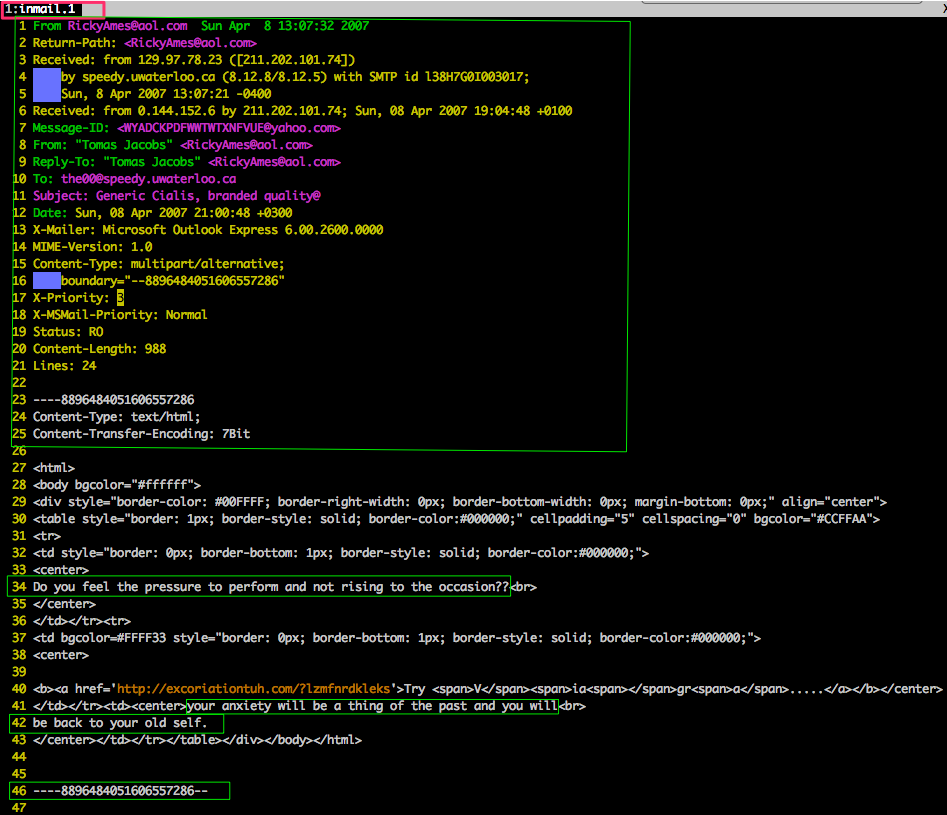
2) email content, for example: ./data/inmail.1:
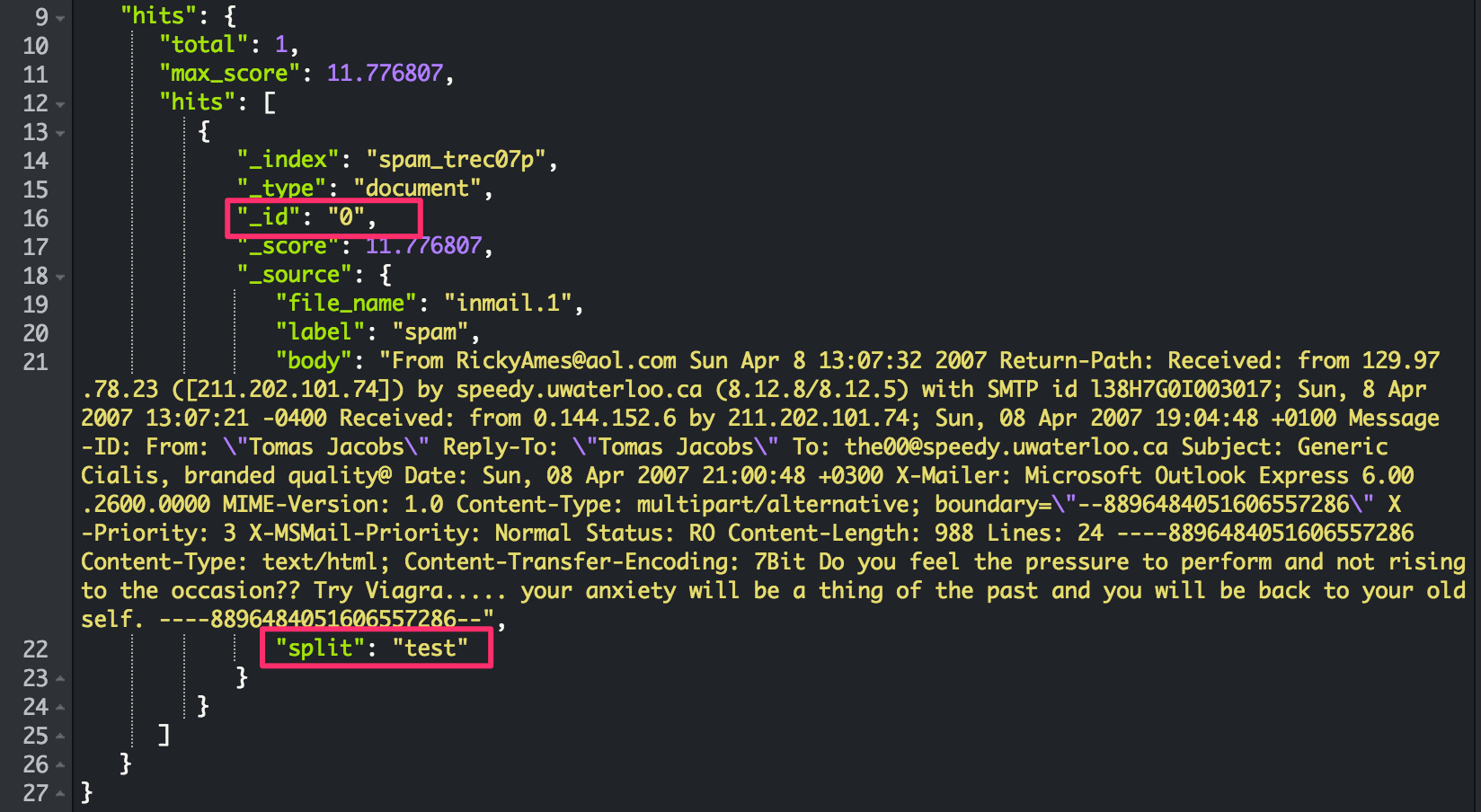
Step 1: Index all Spam Trec07 files into elastic search: For example: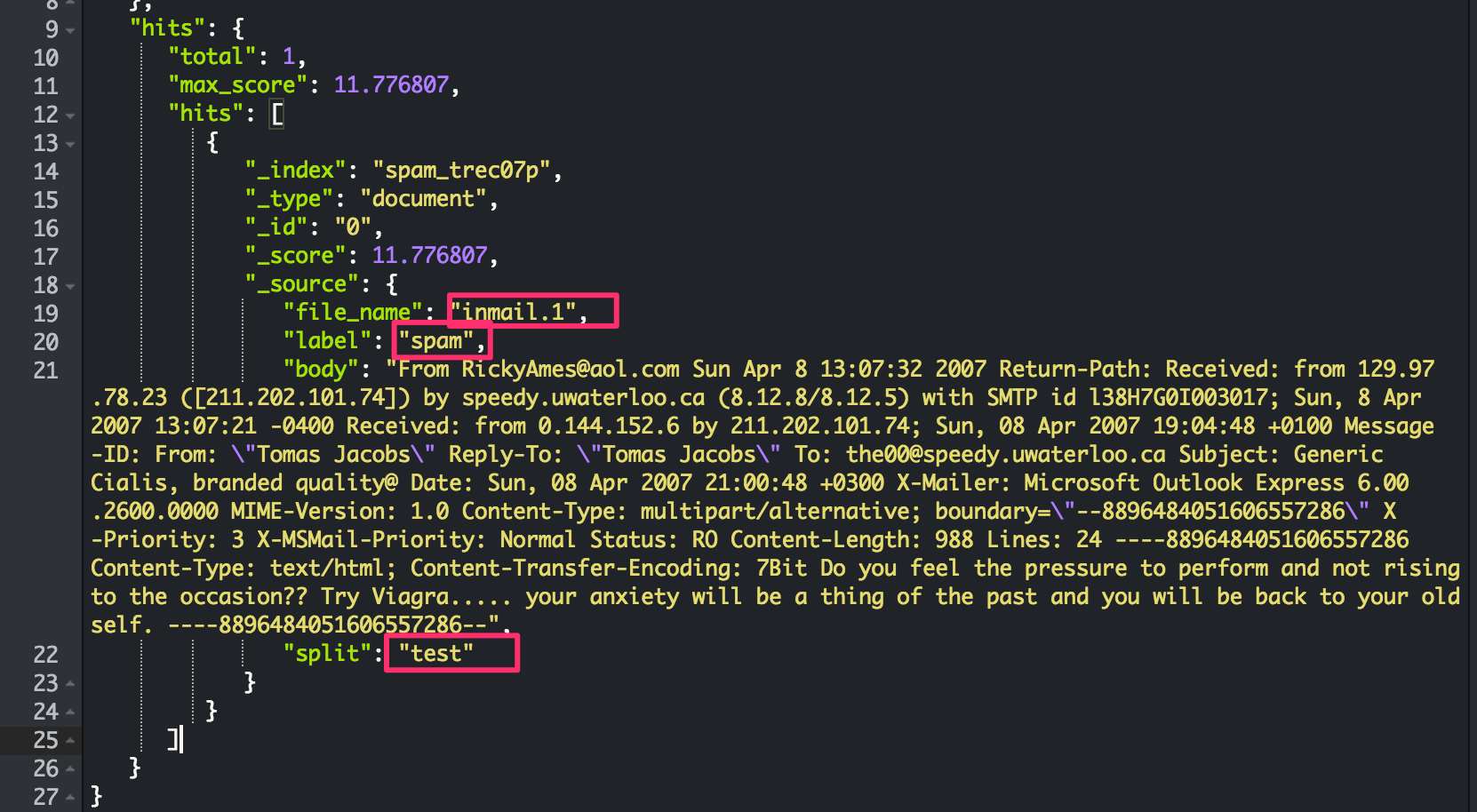
Each document includes: label(spam or ham), body(email contents), split(train or test [4:1 splitting rate.]).
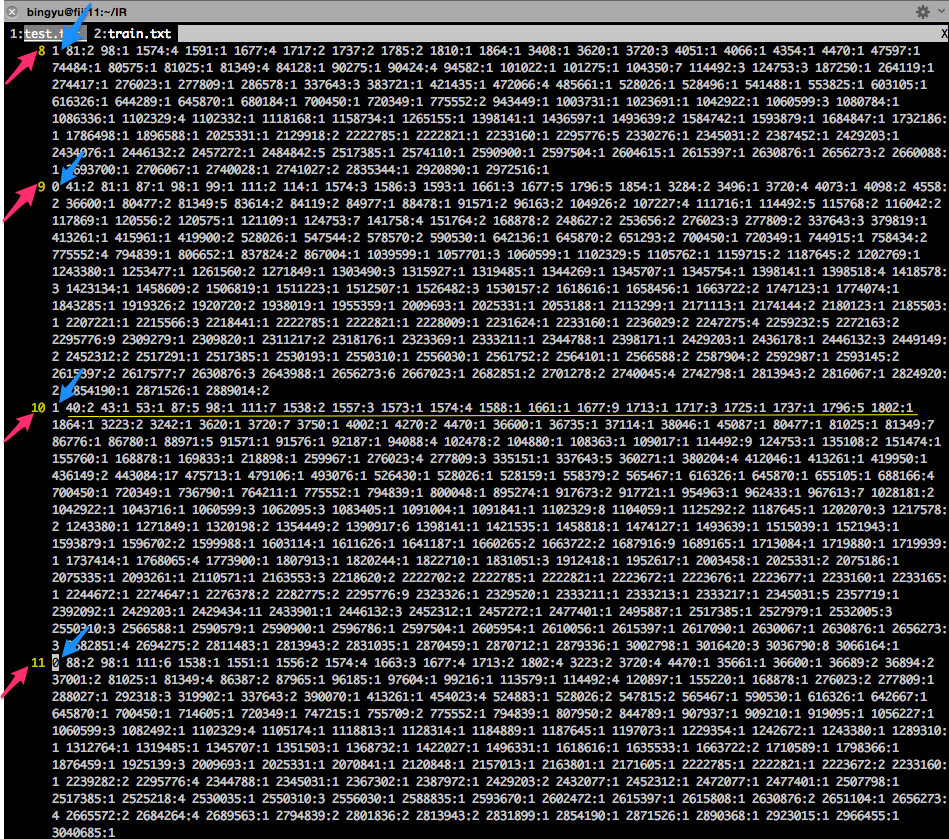
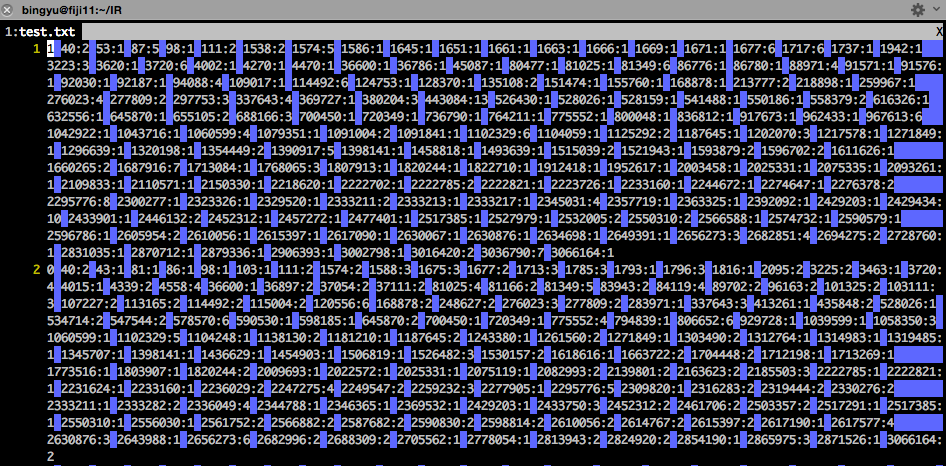
———————————> dump data from Step 1 into feature matrix: train.txt, test.txt.
Solve 3 main problems:
1) red arrow: each line in feature matrix stands for which email from elastic search.
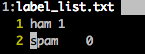
2) blue arrow: the label here (1, 0) in feature matrix stands for what? (spam or ham).
3) yellow line: each sparse feature: e.g. 40:2 stands for what? (40 stands for each term index, 2 is the tf for the term in this email.)
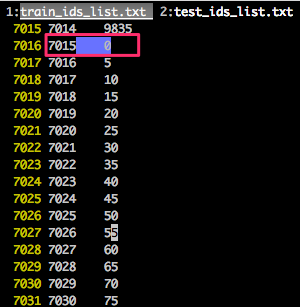
Step 2: get ids for train and test:
train_list = [id_1,id_3...]
test_list = [id_0,….]
Step 3: dump the train and test ids from elastic search into the local files:
For example, named: train_ids_list.txt, test_ids_list.txt.
7015 is the line number of feature_matrix - 1.
0 is the id for inmail.1 in elastic search.
Step 4: dump labels(spam & ham) from elastic search into 0 & 1 in our feature matrix.
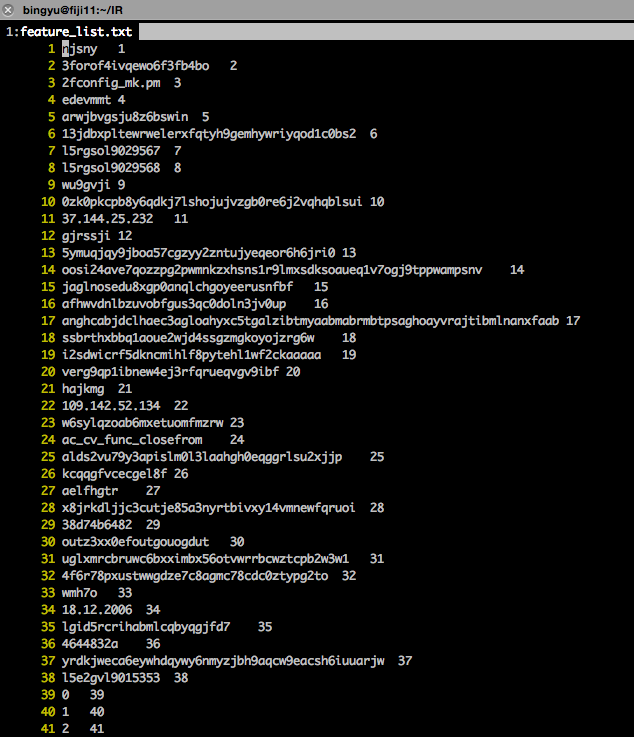
Step 5: build feature index list from training set.
This step is to map each term into unique index number, e.g.
Step 6: dump train/test into feature matrix.
index:value:
index is based on feature_list.txt
value is the tf count, you can use tf-idf or other score from elastic search.
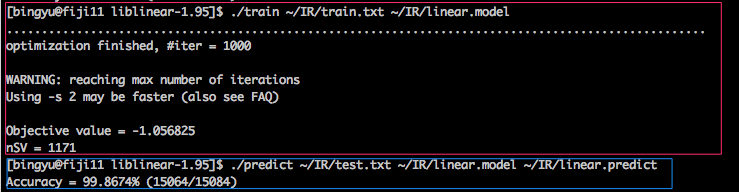
Step 7: Running lib linear classification on train.txt, and test.txt