Dat Huynh’s innovative approach to machine learning nabs a JP Morgan Ph.D. fellowship
Author: Madelaine Millar
Date: 09.02.21
Machine learning works a little differently than human learning does. While a toddler only has to interact with a dog a few times to recognize the animal, an AI needs to crunch through thousands of samples to gain even a partial understanding of the same concept. But what if AI — artificial intelligence, either as an individual system or as a concept — could learn a little more like a child does?
 Dat Huynh
Dat Huynh
Enter Khoury College of Computer Sciences doctoral student Dat Huynh. He is developing a method to train AI using a fraction of the training samples that conventional machine learning uses. Traditionally, a machine learns a separate model for each task: 10,000 images of dogs, labeled “dog,” to train it to recognize a dog, and an additional 10,000 of cats to train it to recognize a cat. Huynh’s method shares information between tasks, breaking complex concepts down into simpler components and using those to leverage the similarities between different subjects. Taking advantage of the similarities between a cat and a dog, for example, allows an AI to learn to recognize each one more quickly and efficiently, and with far fewer labeled training images than two fully separate, fully trained models would require.
 Figure 1. In addition to learning with less data, Huynh’s work also aims to provide interpretation for its predictions. In the domain of fine-grained bird recognition, Huynh and his advisor developed a method that not only recognizes the bird in this image, but also point to the attributes appearing in the images that most influence the predictions. This enables users to trust the model’s predictions.
Figure 1. In addition to learning with less data, Huynh’s work also aims to provide interpretation for its predictions. In the domain of fine-grained bird recognition, Huynh and his advisor developed a method that not only recognizes the bird in this image, but also point to the attributes appearing in the images that most influence the predictions. This enables users to trust the model’s predictions.
According to Huynh’s Ph.D. advisor Ehsan Elhamifar, Huynh’s research is a significant advance over traditional AI training methods, which are difficult and expensive to scale up.
“Data labeling [to create training samples] is a very costly and, in some cases, complex process — imagine labeling frames of videos that are several hours long. In some cases, such as classifying different clothing types or species of closely related families of animals or plants, labeling can be done only by experts and professionals, adding to the complexity and cost of the process,” explained Elhamifar. Furthermore, systems in the real world will encounter concepts they’ve never seen before, and for which they don’t have training data; traditional AI has difficulty adapting to these scenarios.
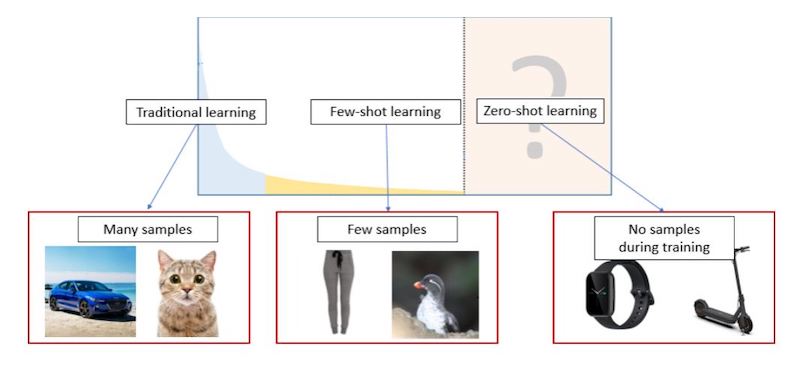 Figure 2. Traditional machine learning focuses on common classes with sufficient training samples. However, many real-world applications involve rare classes that are hard to collect samples for (such as specific types of clothing, or individual species). Moreover, in the real world AI also needs to deal with classes without any training samples, as the object in question might not have been invented during data collection time (such as the latest technologies). Huynh’s research focuses on the new paradigm of few/zero-shot learning, which trains AI to recognize classes with few or no training samples.
Figure 2. Traditional machine learning focuses on common classes with sufficient training samples. However, many real-world applications involve rare classes that are hard to collect samples for (such as specific types of clothing, or individual species). Moreover, in the real world AI also needs to deal with classes without any training samples, as the object in question might not have been invented during data collection time (such as the latest technologies). Huynh’s research focuses on the new paradigm of few/zero-shot learning, which trains AI to recognize classes with few or no training samples.
What’s the significance? “The outcome of [Huynh’s] research will have a big impact on real-world problems including robotics, autonomous driving, and health-care applications, in which labeling is costly and we keep encountering new classes and concepts as the systems work in real-time,” said Elhamifar.
From ‘outside the mainstream’ to fellowship winner
Potential applications for Huynh’s research go well beyond the dog-and-cat scenario. Huynh pointed out two additional benefits to being able to train AI with fewer training samples: making machine learning more accessible and reducing its biases. First, he said, “It’s going to democratize machine learning to developing countries, where you don’t have large facilities to collect 10,000 training samples.” Fewer training samples can be processed in smaller data facilities, he pointed out.
“The second [advantage],” continued Huynh, “is that you can control what it learns. So, these days, we have to learn with a large number of training samples, and there’s no way you can control the quality of them.” In other words, hand-selecting thousands of training images is prohibitively time-intensive, so a machine-learning system simply draws on the large pool of images – unedited, uncurated – that are available. “That’s why these [methods] often result in unwanted bias,” said Huynh, elaborating, “If you [train AI] with a lot of black cars, then what it learns is to recognize only black cars. It does not recognize yellow cars, green cars — it’s similar for human people. If you reduce the amount of training samples, you can inspect whether the training samples are unbiased and diverse enough.” And then, if needed, the training samples can be improved to better represent the concept of “car” — or “human.”
Initially, many of Huynh’s discoveries lay outside the mainstream of the machine-learning industry.
“I once went to a conference…and I talked to a researcher over there, and then when I introduced that I was working on reducing the number of training samples, the PI just immediately dismissed my research,” recalled Huynh. “He said ‘Look, these days big companies can collect thousands of training samples. The training sample will not be the bottleneck of their model, training samples will not be a problem worth working on.’”
While Huynh admitted, “It’s very hard to listen to that and continue working on research projects,” he believed in the value of this work and persisted.
Within the last few years, his research has started to gain traction. Huynh was recently a recipient of the JP Morgan Ph.D. fellowship, which is awarded to Ph.D. students whose research has financial applications that align with the JP Morgan business model. In Huynh’s case, being able to train AI with few or no training samples would allow companies to use AI to conduct market research on brand-new concepts or product ideas. If the thousands of sample images needed to train an AI to recognize a potential new product already existed, the market would be so saturated with that product that there would be no reason to develop it any further. AI-enabled market research on new ideas would need to work in an environment of scant sample images.
The prestigious fellowship — which will cover funding and a stipend for the coming year — offers Huynh a greater degree of research freedom than he’s had in the past. One of 15 fellowship recipients, he will also be connected with researchers from JP Morgan, having the opportunity to intern with them next summer.
Vision for his research and advice to other students
Huynh is planning to use his increased research freedom as a fellow to continue to refine and improve his methods, developing ways to quickly train AI to extract more and more useful information.
“I would like the algorithm to make more fine-grained predictions. What my algorithm is predicting so far is just what’s appearing in an image, whether it’s a dog or a cat or a car — it can’t segment the object out of the image,” he said. In other words, while the existing algorithm can tell you whether there is a dog in the picture, it can’t tell you where the dog is and where it isn’t, or what it’s doing. “I think that now, if I can make the algorithm a more detailed and vibrant application, it can have a larger impact, because people are not only interested in what appears on the scene, but where it is, how the object fits into the overall context.”
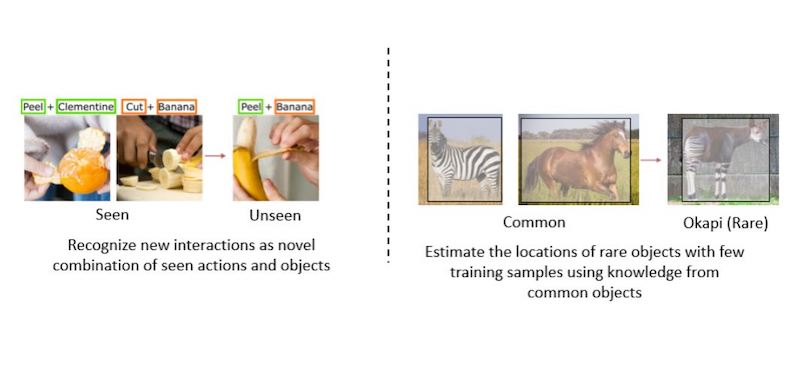 Figure 3. So far, Huynh’s works mainly address the problem of object recognition. His future directions would be to recognize human-object interactions, or to estimate the spatial extension of objects in images. The main emphasis would be to perform these tasks with as few training samples as possible.
Figure 3. So far, Huynh’s works mainly address the problem of object recognition. His future directions would be to recognize human-object interactions, or to estimate the spatial extension of objects in images. The main emphasis would be to perform these tasks with as few training samples as possible.
As Huynh’s hard work on a subject in a specialized niche of computer science has started to pay off, he has two pieces of advice to offer to other students: focus on your fundamentals, and then pursue your passion.
“Getting a good foundation is really important. The foundation here is that you not only learn the trendy techniques, but you should be empowered to learn more classic techniques [too]… Most of the current state-of-the-art techniques were actually techniques 20 years ago, but they put some twists in there to make them work with the latest hardware,” he said. He gave the example of neural networks, a type of “deep learning” machine learning that has been around in concept since the 1940s but wasn’t widely adopted until 2012, when graphics cards sped up computation enough to make the technique viable.
“More importantly,” he advised, “you have to find something [to research] that you really like. [When working on] the hottest topic, the competition is very fierce, so if you don’t have some breakthrough techniques it’s very hard to publish a paper. If you figure out something a bit specialized to you and you really like it, maybe other people won’t appreciate it at first, but once you make some progress?” Promising, original work attracts notice, he believes. Another benefit of pursuing your own research path? Huynh added, “Certainly, you will make your life easier, rather than competing with big companies on the hottest techniques.”
Subscribe to the Khoury College newsletter
The Khoury Network: Be in the know
Subscribe now to our monthly newsletter for the latest stories and achievements of our students and faculty